![]()
Artwork from Nuxt3
Protocol
🧪 一个用于快速复现请求协议的 Web 开发模板。


为什么我要写这样的一个模板(网站)
我曾经是做 API 请求的,经常要模拟某些请求(协议复现)。所以写过比较多的 api 请求代码,在此期间尝试编写过许多代码方式和软件形态。但都不令我满意,不是过于繁琐,就是开发太慢,都达不到我想要的预期。尤其是开发体验,可以说是苦不堪言。
就在前段时间接触了 SSR 框架(Nuxt3)与 Serverless Function,并用其写了一些项目,如 api-service 。而某了个羊刷次数的网站的实现,则让我意外发现这貌似就是我理想中的的协议复现最佳实现?于是我立马开启了 VSCode,将我的这一想法用代码的方式来实现出来,在经历了两周几乎不间断的开发,最终达到了我的预期效果!
在 模拟请求|协议复现方案 这篇文章中我对协议复现的一些方案总结,而这篇就是对 SSR 框架方案的一个具体实践。
技术栈
这个模板基于Nuxt3开发的,该框架拥有全栈开发能力(即全栈框架),并有诸多模块,即装即用。同时由于采用Serverless Function 方式来定义 api 接口,可以轻易地部署在自有服务器或Vercel, Netlify这样的平台上。由于要做到敏捷开发,该模板集成了Naive UI 组件库,组件库的质量足够胜任常规前端业务开发。此外还封装了一些我个人的所用到的工具库以提高开发效率。
为此我给这个模板起名 Protocol,即协议,也可以认为是礼仪。一个用于快速复现请求协议的 Web 开发模板。
废话不多数,就正式来介绍下 Protocol。
目录结构
protocol
├── assets # 前端静态资源文件
├── components # 组件
├── composables # 组合式API
├── content # content 模块
│ ├── changelog.md # 更新日志
│ └── help.md # 帮助说明
├── data # 持久化数据
│ └── db
├── layouts # 布局
├── nuxt.config.ts # nuxt 配置文件
├── package.json # 依赖包
├── pages # 页面
├── plugins # 插件
├── public # 服务端静态资源文件
│ └── logo.svg
├── server # 服务端文件
│ ├── api # 后端接口
│ └── protocol # 协议请求逻辑代理
├── stores # pinia 状态管理
│ └── user.ts # 用户状态
├── types # 类型定义
│ └── user.d.ts # 用户类型声明文件
├── ecosystem.config.js # pm2 配置文件
├── nitro.config.ts # nitro 配置文件
├── app.config.ts # 前端配置文件
└── app.vue # 入口文件
从这个项目的目录结构中其实就可以看出,本项目是集成了全栈能力,并且使用 Vue 与 Node 来编写前端与后端,并不会产生前后端分离的分割感,只需要打开一个项目即可开始工作。这得益于Nuxt3 与 Nitro。
由于是基于 Nuxt3 开发的,所以使用该项目是需要一些 SSR 开发经验。如果你还没有接触 SSR,可以根据你熟悉的前端框架选择对应的 SSR 框架来尝试体验一番。都要 2023 年�了,不会还有前端程序员没用过 SSR 框架吧。
基本功能
全栈开发
这里我不想过多介绍 Nuxt3 的基本功能与使用,在我的一个 基于 Nuxt3 的 API 接口服务网站 的项目中,有简单介绍过 Nuxt3,有兴趣可以去看看。
这里你只需要知道 Nuxt3 具有全栈开发的能力,如果你想,完成可以基于 Nuxt3 这个技术栈来实现 Web 开发的前端后端工作。
类型提示
首先,最重要的就是类型提示,对于大多数 api 请求而言,类型往往常被忽略。这就导致不知道这个请求的提交参数、响应结果有什么数据字段。举个例子
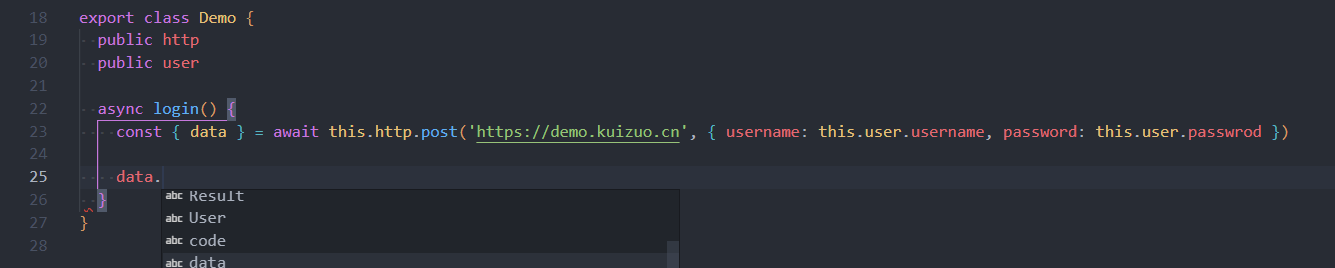
这是一个 post 请求用于实现登录的,但是这个响应数据 data 没有任何具体提示(这里的提示是 vscode 记录用户常输入的提示),这时候如果一旦拼接错误,就会导致某个数据没拿到,从而诱发 bug。同理提交的请求体 body 不做约束,万一这个请求还有验证码 code 参数,但是我没写上,那请求就会失败,这是就需要通过调试输出,甚至需要抓包比对原始数据包才能得知。
最主要的是没有类型约束的情况下,非常容易出现出现访问的对象属性不存在,做 js 开发的肯定经常遇到如下错误提示。
Uncaught TypeError: Cannot read properties of undefined (reading 'data')
有太多很多时候就是因为没有类型,无形间诱发 bug。就极易造成开发疲惫,不愿维护代码,这也是很多做 api 接口都常常忽视的一点。包括我之前也是同样如此。
对于 js 而言,上述情况自然是解决不了,但这种场景对于 ts 来说在适合不过了。所以 Protocol 自然是集成了 ts,并且有良好的类型提示。下面展示几张开发时的截图就能体会到,当然你前提是得会 ts 或者看的懂 ts。
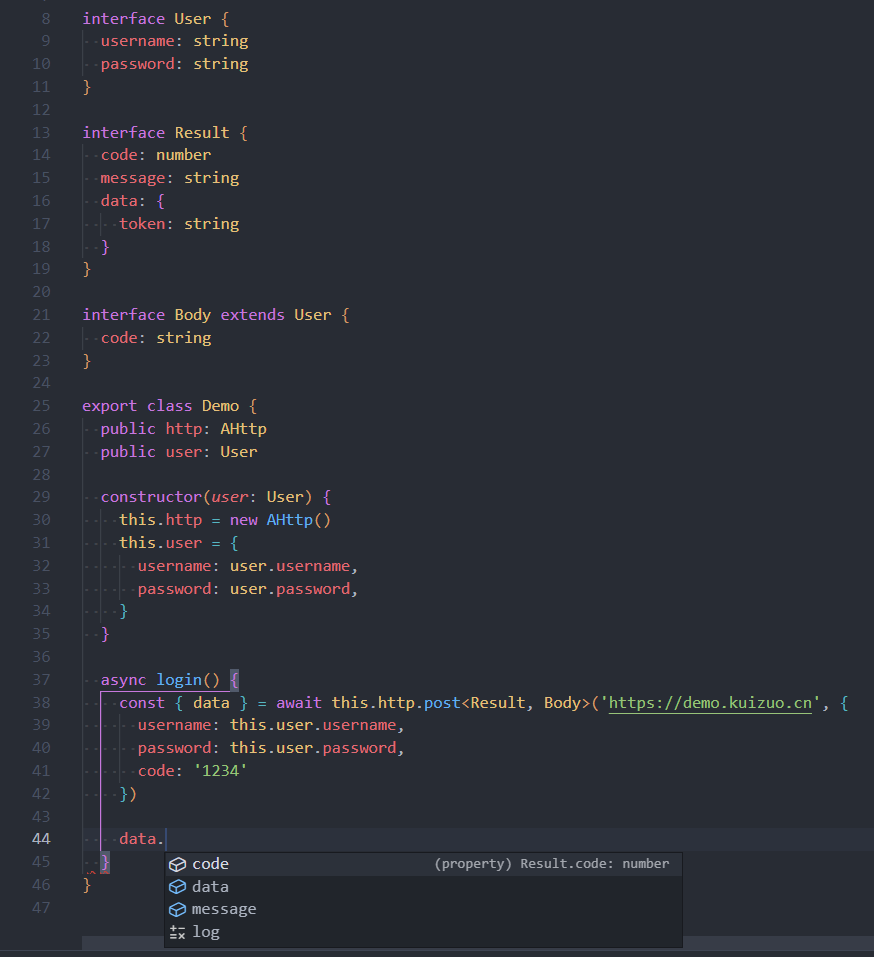
上面的类型提示演示代码仅仅作为体现类型的好处,将类型定义(interface,type 等)和核心逻辑都在同一个文件自然不好,容易造成代码冗余。实际开发中,更多使用命名空间,将类型写到 ts 声明文件.d.ts 中。比如将上面的改写后如下
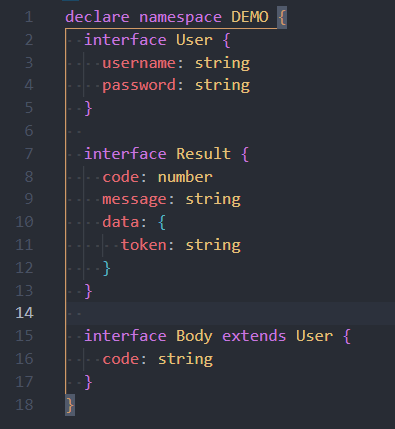
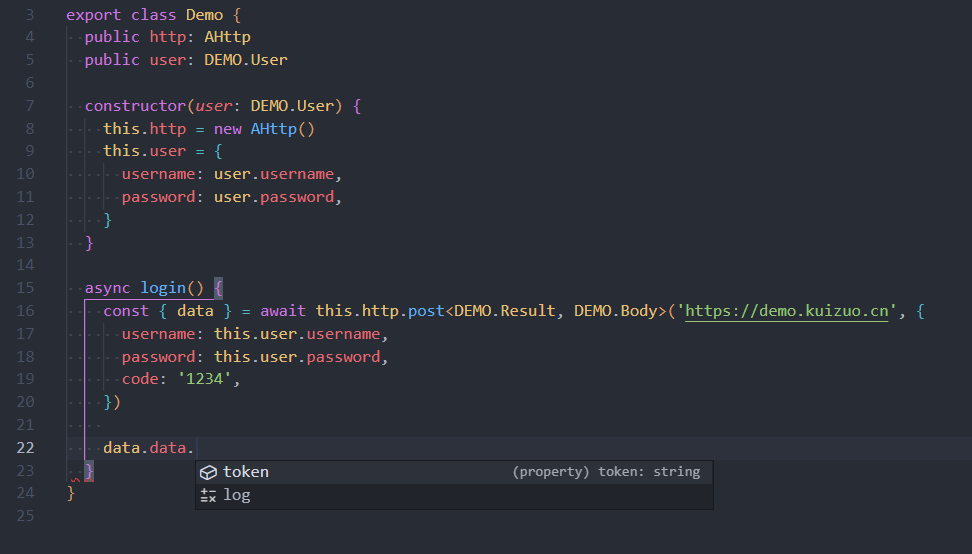
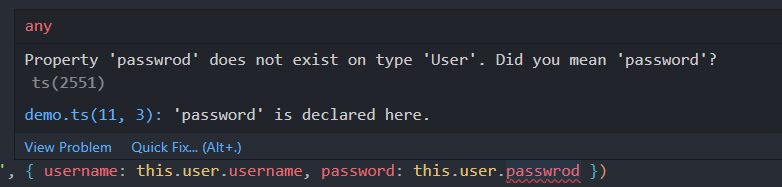
就在我写这篇文章做代码演示的时候,又发生了拼写错误,如下图。由于使用 ts 类型与 eslint,所以在开发时的问题我就能立马发现,而不是到了运行时才提示错误。
有了类型提示能非常有效的避免上述问题。同时 ts 并不像 java 那样的强类型语言,你完全可以选择是否编写 ts 的类型(type 或 interfere),这由你决定,你乐意都可以将 typescript 写成 anyscript,因为确实有些人确实不喜欢写类型。
ts 的类型提示仅是其次,此外还配置了 eslint 对代码检查,让代码在 2 个空格缩进,无分号,单引号等代码规范下。保证代码质量,而不会出��现这边一个分号,那边来个双引号的情况。
工具库
要想在实际项目中使用,还需要做很多功课,例如数据格式转换,编码,加解密,cookie 存储,IP 代理等等。这段时间也特此对常用工具封装成 npm 包,也就是 @kuizuo/http 与 @kuizuo/utils。
大部分的代码我都会采用最新的 ECMAScript 标准来编写,目的也是为了简化代码,减少不必要的负担。
数据库
既然是全栈框架,那么必然少不了数据库的存取,nitro 自然是提供了数据存储选择,即 unjs/unstorage。使用特别简单:
await useStorage().setItem('test:foo', { hello: 'world' })
await useStorage().getItem('test:foo')
不指定则使用内存,当然了想要持久化配置,nitro 也提供了相关配置
// nitro.config.ts
import { defineNitroConfig } from 'nitropack'
export default defineNitroConfig({
storage: {
redis: {
driver: 'redis',
/* redis connector options */
},
db: {
driver: 'fs',
base: './data/db',
},
},
})
并根据不同前缀(根据 nitro.config.ts 中的 storage 对象的属性)存储在不同存储位置,如
// 存内存缓存中
await useStorage().setItem('cache:foo', { hello: 'world' })
await useStorage().getItem('cache:foo')
// 存db中
await useStorage().setItem('db:foo', { hello: 'world' })
await useStorage().getItem('db:foo')
// 存redis中
await useStorage().setItem('redis:foo', { hello: 'world' })
await useStorage().getItem('redis:foo')
从目前来看,unjs/unstorage并没有提供 sql 数据库的方案。不过对于这类项目而言,似乎也没有上 sql 数据库的必要,文件和 redis 就足以了。如果需要也可以自定义 drivers。
由于 Vercel 是不支持文件读写的,所以想要文件方式数据存储功能就行不通,需要更换存储方案,比如远程 redis 数据库。
如果是部署到自由的服务器(通常是 Linux 系统),则还需要分配相应的读写权限。
用户凭证存储
通常来说,有两种用户凭证,Cookie 和 Token,有了上述数据存储的方案,存取用户凭证并不是什么难题。不过用户凭证更多的是用来鉴权的,这时候就需要配置前端Middleware 和后端 Middleware,至于选择哪种,根据实际网站情况来选择即可。
更新日志与帮助说明
我提供了两个 md 页面,更新日志(ChangeLog)和帮助说明(Usage),如果需要更新内容,在根目录下 content 文件夹中找到对应文件修改即可。
如果你想在创建新的 md 页面只需要在 content 中新建一个文件(如 test.md),在页面路由创建同名 vue 文件(test.vue),将下方的 path 修改相应文件名即可。
<script setup lang="ts">
definePageMeta({
layout: 'markdown',
})
</script>
<template>
<div>
<ContentDoc class="prose text-left" path="/test" />
</div>
</template>
打包与部署
传统的 node 后端框架,通常需要将原文件或者打包后的文件放到服务器上,执行 npm i 下载 package.json 里的依赖文件,然后执行运行命令启动。这一步骤的下载依赖就尤为致命,因为通常下载依赖将会特别耗时。
但 Nuxt3 则是会将前后端的资源文件,打包到 .output 文件夹下,以本项目为例,打包的大小为 14.6MB,gzip 压缩为 3.11MB(写本章时的记录),如果不使用Content 模块体积将会更小。打包完成提示如下
Σ Total size: 14.6 MB (3.11 MB gzip)
√ You can preview this build using node .output/server/index.mjs
然后你只需要将 .output 整个文件夹放到服务器上,并且安装好 node 环境,输入 node .output/server/index.mjs 即可启动项目,默认端口为 3000。当然也可以通过 pm2 的配置文件来启动,配置文件如下
module.exports = {
apps: [
{
name: 'Protocol',
exec_mode: 'cluster',
instances: '1',
env: {
NITRO_PORT: 8010,
NITRO_HOST: 'localhost',
NODE_ENV: 'production',
},
script: './.output/server/index.mjs',
},
],
}
接着执行 pm2 start ecosystem.config.js --env production 即可运行。相比传统需要手动下载依赖的方式,Nuxt3 则是直接将 web 项目实际所需要的依赖都打包在一起,只需要在有 node 环境下机器中就可以立马运行,无需等待依赖下载。
如果部署在 Vercel 或 Netlify 就更轻松了,根据官方的��步骤即可做到一键部署。
开发流程(形态)
介绍完工具库,如果不介绍下开发流程,很多人都不知道该如何起手,这里我会用 Github 的 api 作为案例演示,也就是模板源代码中所演示的那样。当然,后续我会根据一些实战项目考虑弄个案例展示(在写中),以来方便使用与完善该模板。毕竟如果开发者自己都不愿意用,又怎么去说服他人来使用呢。
修改内容
如何修改某文字内容或某图标,这里就不再赘述了,Ctrl + Shift + F 搜索你想修改的内容并修改即可。大部分能修改的配置都写在了 app.config.ts 下。
export default defineAppConfig({
title: 'Protocol',
description: '一个用于快速复现请求协议的Web开发模板。',
author: {
name: 'kuizuo',
link: 'https://github.com/kuizuo',
qq: 'https://im.qq.com/',
wx: 'https://wx.qq.com/',
},
})
通过 const appConfig = useAppConfig() 获取配置对象数据。
定义协议复现逻辑代码(重要)
这里以调用 Github 的 api 为例,因为业务相对简单,所以使用的是静态方法来调用,简单展示一下代码
import { AHttp } from '@kuizuo/http'
const http = new AHttp({ baseURL: 'https://api.github.com' })
export class Github {
static async getUser(username: string) {
const { data } = await http.get<API.User>(`/users/${username}`)
return data
}
static async getRepos(username: string) {
const { data } = await http.get<API.Repo[]>(`/users/${username}/repos`)
return data
}
}
我个人是习惯也喜欢将逻辑部分用 class 的方式来编写,也推荐用这种去定义这些业务逻辑代码。这里我举个例子来说明,假设现在有一个博客网站,有登陆、获取博文列表、评论等功能。那么我会这么写
import { AHttp } from '@kuizuo/http'
interface User {
username: string
password: string
}
export class Blog {
public http: AHttp
public user: User
constructor(user: User) {
this.http = new AHttp({ baseURL: 'https://blog.kuizuo.cn' })
this.user = User
}
async login() {
// login logic code
}
async getBlogList() {
// getBlogList logic code
}
async comment(id: number) {
// comment logic code
}
}
定义完这些后,我只需要实例化一个对象 account,调用 login 方法即可登录,后续的获取博文列表与评论操作我只需要拿这个 account 来操作即可。
const account = new Blog({ username: 'kuizuo', password: '123456' })
await account.login()
const blogList = await account.getBlogList()
await account.comment(1)
如果想换一个账号操作,就需要重新按照上面的方式实例化一个新的对象,拿这个对象操作即可。
并且这种方式在迁移代码的时候尤为方便,可以直接将这份代码放到不同的 Node 项目中来运行。
通常也是在这一流程中,会编写大量的类型代码,来完善整个项目,保证代码的健壮。通常我会在同文件下或者在 types 下定义 .d.ts 声明文件,通过声明文件与命名空间,无需导入即可全局使用类型。
定义后端数据接口
定义完复现协议的逻辑代码后,那么就到前后端数据交互部分了,首先定义后端的接口,由于上面我们已经定义好了协议复现逻辑代码,这边只需要导入使用即可。就像下面这样
import { Github } from '~~/server/protocol/github'
import { ResOp } from '~~/server/utils'
export default defineEventHandler(async event => {
const { username } = event.context.params
const user = await Github.getUser(username)
if (!user.login) return ResOp.error(404, user.message ?? 'User not found')
await useStorage().setItem(`db:github:user:${username}`, user)
return ResOp.success(user)
})
这一部分的代码建立在 Serverless Function 上,每一个接口都是以函数的方式对外暴露出去。这些代码会根据文件位置生成对应的路由,比如说上面的文件为 server/api/user/[username].ts,就映射为 /api/user/:username,前端请求 /api/user/kuizuo 通过event.context.params.username 便可以拿到 username 的值为 kuizuo。
至此后端部分就暂以告告落。
定义前端状态管理
对于前端而言,肯定是需要全局管理一些数据状态的,这样能够在不同的组件间共享数据,并且需要持久化这些数据,以保证下次用户再次打开网页的时候无需向后台请求数据,pinia 持久化使用到了 pinia-plugin-persistedstate 插件。
同时在状态管理中,会定义一些方法来调用后端接口。如下演示
import { useMessage } from 'naive-ui'
export const useUserStore = definePiniaStore('user', () => {
const user = ref<API.User | null>(null)
const repos = ref<API.Repo[]>([])
const message = useMessage()
async function getUser(username: string) {
const { data } = await http.get<API.User>(`/api/user/${username}`)
if (data.login) {
user.value = data
message.success('获取成功')
}
else {
message.error(data.message)
}
}
async function getRepos() {
const username = user.value?.login
const { data } = await http.get<API.Repo[]>(`/api/repo/${username}`)
repos.value = data
}
async function reset() {
user.value = null
repos.value = []
}
return {
user,
repos,
getUser,
getRepos,
reset,
}
}, {
persist: {
key: 'user',
},
})
这里的 http 是经过封装的,因为返回数据格式如:{"code":200,"data":{},"message":"success"} ,但对于业务逻辑而言,我们通常只需要关注 data 里面的数据,而请求的状态 code 与信息 message 则不是所要着重关系的对象。
至于想要返回原数据,还是带有 code, message 的数据,因人而异,我更喜欢后者将数据格式规范化,这样我就能知道本次请求的状态结果,在响应拦截器中就能够进行预先处理。
在 vue 组件中只需要使用演示如下
<script setup lang="ts">
let username = $ref('kuizuo')
let loading = $ref(false)
const userStore = useUserStore()
const user = $computed(() => userStore.user)
async function getUser() {
loading = true
try {
await userStore.getUser(username)
} finally {
loading = false
}
}
</script>
编写前端页�面与组件
这一部分自由发挥即可了,这里我是集成了 NaiveUI 与 Unocss,足够应对大部分的前端开发需求。没什么过多要说的了。
流程总结
整个开发流程就是这样的,如果我想要添加一个功能,用于获取 Github 用户已点的 Star 项目列表,那么按照上面流程将会清晰的实现出来。
这里仅举调用 Github api 为例,想调用其他第三方的 api 都不成问题,本模板只提供一个这样的开发流程(形态)能够帮助快速实现 Web 站点开发,同时极易部署,做到敏捷开发。
对比传统前后端分离的开发流程,这种开发流程可以说更加清晰,更加规范,更加高效。
一些问题
遇到图片防盗链怎么办?
我的做法相对比较简单粗暴,直接在图片中添加referrerpolicy='no-referrer' 就像下面这样。
<img src="src" referrerpolicy="no-referrer" />
如果你想要集成到 HTML 或者 CSS ,可以直接在 <head> 标签下添加如下代码.
<meta name="referrer" content="no-referrer" />
参阅Referrer-Policy - HTTP | MDN (mozilla.org)
跨域问题
几乎不会遇到跨域问题,因为所有的接口都相当于转发过一遍,不是由前端直接发送,而是后端接收到后,通过服务器来进行发送,然后将数据在返还给前端。
考虑做的
编写一个后台管理系统
这个模板如果要实现鉴权是相对比较简单的,前后端配置Middleware 即可实现。使用 cookie 和 token 都随意,甚至第三方的登录。
但这时数据多了,难免需要去管理数据,不如专门为此编写一个后台管理系统,同时提供一个鉴权相关的功能。主要还是借助 ntrio 来开发,毕竟提供全栈开发能力,要实现只是时间开发的问题。
使用 tauri 编译跨平台程序
编译成跨平台程序有一个好处,就是所有的流量请求与接收都是存放在用户的机器中,就相当于传统的桌面应用开发。而部署在 Web 端请求流量的压力都将会来到服务器上,就避免不了用户量大,导致请求缓慢,甚至 ip 被封禁的问题。
由于我暂且还不会 tauri 开发,也还不会 rust,所以这个功能估计得到寒假才有可能去实现了。electron 占用比较大的资源空间,不作为跨平台框架优先选择。
写在最后
这种开发形态自打我接触协议复现到前端开发我就考虑过,但奈何在没接触 ssr 框架之前,这种开发形态多半是需要前后端分离,要么使用模板语言,这样接口交互方面将会十分繁琐,开发效率过于低效。
因此当我发觉 ssr 框架的可行性后,我几乎整整花费了两周的时间在不断的探索与完善中,希望将其编写成一个我日后随时都会用到的模板,即写即用,极速上线。因为这样的开发场景对我来说太过于常见了,而很多时间就是因为没有一个相应的模板与工具库,代码总是东凑西凑,后续维护与测试总是花费不小的时间去解决。
目前这种方案已有初步雏形,由于一些特殊的因素,我��并未将已经写过的站点作为案例放在这上面作为演示,而将 Github api 作为演示,后续大概率会弄个案例展示供参考学习。
后续我还是会不断去完善与维护该项目,并基于该项目去重构我的一些项目。
本模板仅仅是 web 模板,任何开发者用该模板做什么样的站点都与本人无关。仅作为个人技术专研,仅供学习参考。